Index
- Array Processor
- Parallel Processing and Flynn’s taxonomy
- Distributed Shared Memory Architecture (DSM)
- Cluster Computers
- Non von Neumann Architectures
Array Processor
Array Processor performs computations on large array of data. These are two types of Array Processors: Attached Array Processor, and SIMD Array Processor
Attached Array Processor
To improve the performance of the host computer in numerical computational tasks auxiliary processor is attached to it.
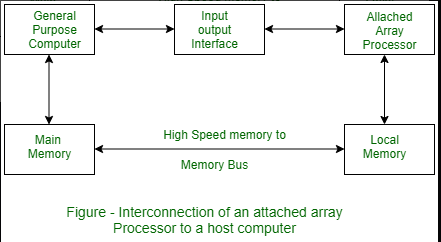
Attached array processor has two interfaces:
- Input output interface to a common processor.
- Interface with a local memory.
Here local memory interconnects main memory. Host computer is general purpose computer. Attached processor is back end machine driven by the host computer.
The array processor is connected through an I/O controller to the computer & the computer treats it as an external interface.
SIMD array processor
This is computer with multiple processing unit operating in parallel Both types of array processors, manipulate vectors but their internal organization is different.
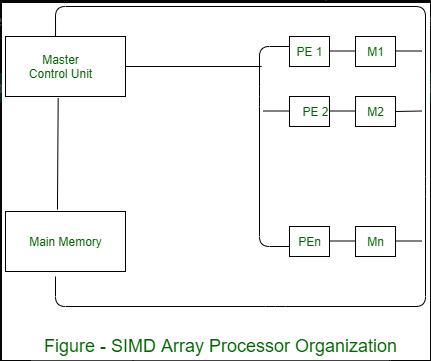
SIMD is a computer with multiple processing units operating in parallel.
The processing units are synchronized to perform the same operation under the control of a common control unit. Thus providing a single instruction stream, multiple data stream (SIMD) organization. As shown in figure, SIMD contains a set of identical processing elements (PES) each having a local memory M.
Each PE includes –
- ALU
- Floating point arithmetic unit
- Working registers
Master control unit controls the operation in the PEs. The function of master control unit is to decode the instruction and determine how the instruction to be executed. If the instruction is scalar or program control instruction then it is directly executed within the master control unit.
Parallel Processing and Flynn’s taxonomy
Parallel computing is a computing where the jobs are broken into discrete parts that can be executed concurrently. Each part is further broken down to a series of instructions. Instructions from each part execute simultaneously on different CPUs. Parallel systems deal with the simultaneous use of multiple computer resources that can include a single computer with multiple processors, a number of computers connected by a network to form a parallel processing cluster or a combination of both.
The crux of parallel processing are CPUs. Based on the number of instruction and data streams that can be processed simultaneously, computing systems are classified into four major categories(also known as Flynn's classification or Flynn's taxonomy):
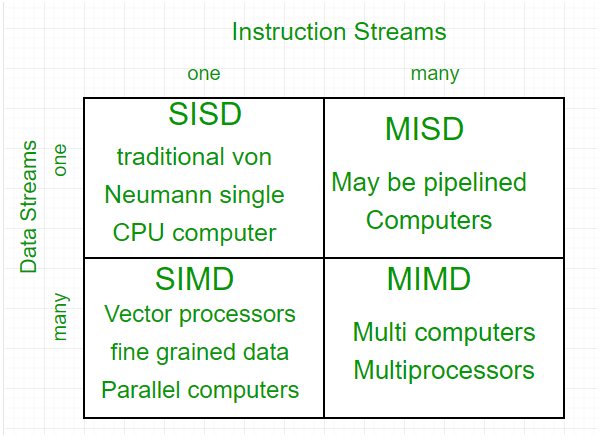
1. Single-instruction, single-data (SISD) systems –
An SISD computing system is a uniprocessor machine which is capable of executing a single instruction, operating on a single data stream. In SISD, machine instructions are processed in a sequential manner and computers adopting this model are popularly called sequential computers. Most conventional computers have SISD architecture. All the instructions and data to be processed have to be stored in primary memory.
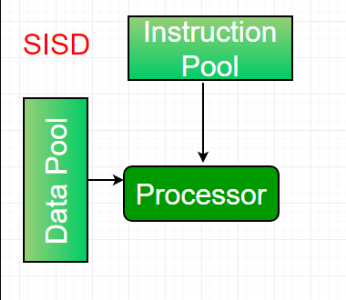
The speed of the processing element in the SISD model is limited(dependent) by the rate at which the computer can transfer information internally. Dominant representative SISD systems are IBM PC, workstations.
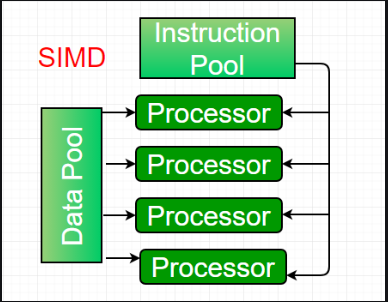
2. Single-instruction, multiple-data (SIMD) systems –
An SIMD system is a multiprocessor machine capable of executing the same instruction on all the CPUs but operating on different data streams. Machines based on an SIMD model are well suited to scientific computing since they involve lots of vector and matrix operations. So that the information can be passed to all the processing elements (PEs) organized data elements of vectors can be divided into multiple sets(N-sets for N PE systems) and each PE can process one data set.
3. Multiple-instruction, single-data (MISD) systems –
An MISD computing system is a multiprocessor machine capable of executing different instructions on different PEs but all of them operating on the same dataset .
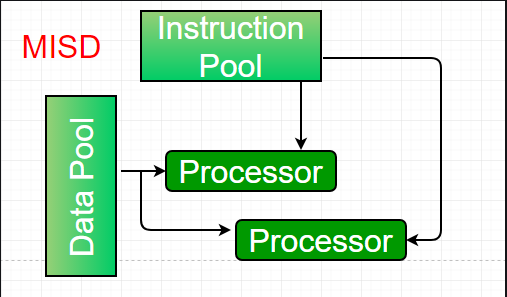
Machines built using the MISD model are not useful in most of the application, a few machines are built, but none of them are available commercially.
4. Multiple-instruction, multiple-data (MIMD) systems –
An MIMD system is a multiprocessor machine which is capable of executing multiple instructions on multiple data sets. Each PE in the MIMD model has separate instruction and data streams; therefore machines built using this model are capable to any kind of application. Unlike SIMD and MISD machines, PEs in MIMD machines work asynchronously.
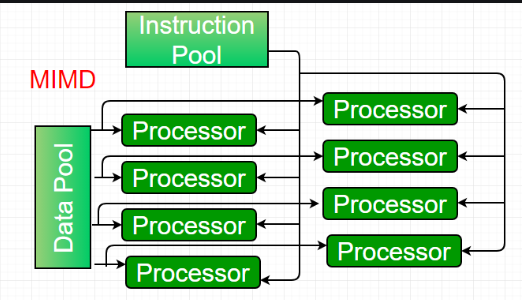
MIMD machines are broadly categorized into shared-memory MIMD and distributed-memory MIMD based on the way PEs are coupled to the main memory.
In the shared memory MIMD model (tightly coupled multiprocessor systems), all the PEs are connected to a single global memory and they all have access to it. The communication between PEs in this model takes place through the shared memory, modification of the data stored in the global memory by one PE is visible to all other PEs.
In Distributed memory MIMD machines (loosely coupled multiprocessor systems) all PEs have a local memory. The communication between PEs in this model takes place through the interconnection network (the inter process communication channel, or IPC). The network connecting PEs can be configured to tree, mesh or in accordance with the requirement.
The shared-memory MIMD architecture is easier to program but is less tolerant to failures and harder to extend with respect to the distributed memory MIMD model. Failures in a shared-memory MIMD affect the entire system, whereas this is not the case of the distributed model, in which each of the PEs can be easily isolated. Moreover, shared memory MIMD architectures are less likely to scale because the addition of more PEs leads to memory contention. This is a situation that does not happen in the case of distributed memory, in which each PE has its own memory. As a result of practical outcomes and user’s requirement , distributed memory MIMD architecture is superior to the other existing models.
Distributed Shared Memory Architecture (DSM)
Distributed shared-memory (DSM) architecture allows processors in a distributed system to share a common address space, even though the memory is physically distributed across multiple nodes. DSM systems provide the illusion of shared memory, simplifying programming while leveraging the scalability of distributed systems. They often require complex mechanisms for maintaining coherence and consistency.
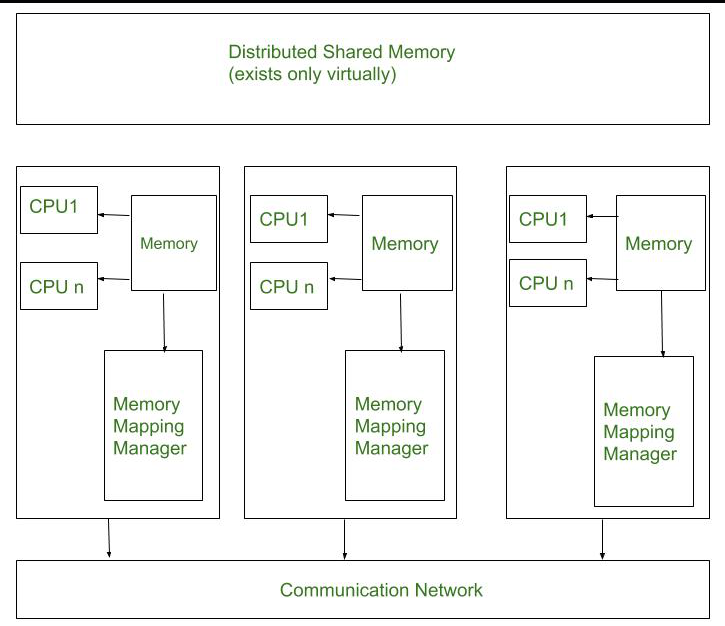
To beat the high forged of communication in distributed system. DSM memo, model provides a virtual address area shared between all nodes. systems move information to the placement of access. Information moves between main memory and secondary memory (within a node) and between main recollections of various nodes.
The architecture of a Distributed Shared Memory (DSM) system typically consists of several key components that work together to provide the illusion of a shared memory space across distributed nodes. the components of Architecture of Distributed Shared Memory :
-
Nodes: Each node in the distributed system consists of one or more CPUs and a memory unit. These nodes are connected via a high-speed communication network.
-
Memory Mapping Manager Unit: The memory mapping manager routine in each node is responsible for mapping the local memory onto the shared memory space. This involves dividing the shared memory space into blocks and managing the mapping of these blocks to the physical memory of the node.
-
Caching is employed to reduce operation latency. Each node uses its local memory to cache portions of the shared memory space. The memory mapping manager treats the local memory as a cache for the shared memory space, with memory blocks as the basic unit of caching.
-
Communication Network Unit: This unit facilitates communication between nodes. When a process accesses data in the shared address space, the memory mapping manager maps the shared memory address to physical memory. The communication network unit handles the communication of data between nodes, ensuring that data can be accessed remotely when necessary.
-
A layer of code, either implemented in the operating system kernel or as a runtime routine, is responsible for managing the mapping between shared memory addresses and physical memory locations.
Each node’s physical memory holds pages of the shared virtual address space. Some pages are local to the node, while others are remote and stored in the memory of other nodes.
Cluster Computers
This is the same as DSM(literally based on DSM).
Cluster computing involves connecting multiple independent computers (often called nodes) to work together as a single cohesive system. This approach leverages the combined computational power and resources of all nodes, enabling the system to perform tasks more efficiently than a single computer could.
Key Characteristics:
-
Node Composition: Each node in a cluster is typically a complete computer with its own CPU, memory, storage, and network interface. Nodes can be heterogeneous (different hardware and software configurations) or homogeneous (identical configurations).
-
Interconnection Network: Nodes are interconnected through high-speed networks such as Ethernet, InfiniBand, or specialized interconnects. The network’s performance is critical for the cluster’s overall efficiency, especially for tasks that require frequent communication between nodes.
-
Distributed Memory: Unlike centralized shared memory architectures, each node in a cluster has its own private memory. Data sharing and communication between nodes are achieved through message passing, typically using libraries like MPI (Message Passing Interface).
-
Scalability: Clusters are highly scalable. Nodes can be added or removed to meet the computational needs, making clusters suitable for a wide range of applications from small-scale tasks to large-scale high-performance computing (HPC) applications.
-
Fault Tolerance: Clusters often include mechanisms for fault tolerance and redundancy. If a node fails, the system can redistribute the workload among the remaining nodes, minimizing the impact of hardware failures.
-
Cost-Effectiveness: Clusters are often built using commodity hardware, making them more cost-effective than specialized supercomputers. This allows organizations to scale their computational resources incrementally.
Advantages:
- High Performance: Clusters can achieve high computational performance by distributing tasks across multiple nodes, making them suitable for data-intensive and compute-intensive applications.
- Flexibility: Clusters can be scaled and reconfigured to meet varying workloads and application requirements.
- Cost Efficiency: Using commodity hardware and open-source software can significantly reduce costs compared to proprietary supercomputing solutions.
Disadvantages:
- Complexity: Managing a cluster, including its software and hardware components, can be complex and require specialized knowledge.
- Communication Overhead: The performance of cluster applications can be limited by the communication overhead between nodes, especially for tightly coupled tasks that require frequent data exchange.
- Energy Consumption: Large clusters can consume significant amounts of power, leading to high operational costs.
Applications:
- Scientific Computing: Clusters are widely used in scientific research for simulations, modeling, and data analysis in fields such as physics, chemistry, and biology.
- Big Data Processing: Frameworks like Hadoop and Spark run on clusters to process large datasets for applications in finance, marketing, and research.
- Web Services and Cloud Computing: Many web services and cloud platforms use clusters to provide scalable and reliable services to users. Companies like Google, Amazon, and Facebook operate massive clusters to handle their computational needs.
- Rendering Farms: Clusters are used in the film and animation industry for rendering complex graphics and visual effects.
Non von Neumann Architectures
Non von Neumann architectures deviate from the traditional von Neumann architecture, where a single control unit fetches and executes instructions sequentially from a single memory space. These alternative architectures aim to overcome limitations such as the von Neumann bottleneck, where the speed of instruction execution is limited by the bandwidth between the CPU and memory.
1. Data Flow Computers
Concept: Data flow computers operate on the principle of data-driven execution. Instead of following a sequential control flow (as in von Neumann architectures), instructions in data flow computers are executed as soon as their input data is available.
Key Features:
- Data Dependency: Instructions are fired (executed) when all their input data are available.
- Parallelism: High levels of inherent parallelism as multiple instructions can be executed simultaneously if their data dependencies are met.
- Tokens: Data items are often represented as tokens that flow through the system, triggering computations.
Advantages:
- Can exploit fine-grained parallelism.
- Avoids the control flow bottleneck typical in von Neumann architectures.
Challenges:
- Complex hardware design.
- Difficult to program and optimize compared to traditional models.
Applications:
- Suitable for applications with significant parallelism and data-driven characteristics, such as scientific simulations and signal processing.
2. Reduction Computer Architectures
Concept: Reduction computer architectures are based on the principle of reducing expressions to their simplest form. This model is closely associated with functional programming, where computations are expressed as the evaluation of mathematical functions.
Key Features:
- Expression Evaluation: Computation is performed by recursively reducing expressions.
- Graph Reduction: Programs are often represented as graphs, where nodes represent operations, and edges represent data dependencies.
Advantages:
- Naturally suited for functional programming languages.
- Avoids side effects, leading to more predictable and reliable code.
Challenges:
- Generally less efficient for imperative programming styles.
- Can be difficult to implement efficiently in hardware.
Applications:
- Used in research and applications where functional programming paradigms are advantageous, such as certain types of algorithmic computations and symbolic processing.
3. Systolic Architectures
Concept: Systolic architectures consist of arrays of processors that process and pass data rhythmically in a synchronized manner, similar to the pulsing action of the heart. This model is designed to efficiently handle regular, repetitive computations.
Key Features:
- Regular Structure: Typically consists of a regular grid of processing elements.
- Data Pipelining: Data flows through the processors in a pipelined fashion, allowing continuous data processing.
- Local Communication: Each processor only communicates with its immediate neighbors, reducing the need for a complex interconnection network.
Advantages:
- Highly efficient for specific tasks such as matrix multiplication, convolution operations, and other linear algebra computations.
- Can achieve high throughput and efficient utilization of processing elements.
Challenges:
- Limited to applications that can be mapped to the systolic array structure.
- Less flexible compared to more general-purpose architectures.
Applications:
- Commonly used in digital signal processing (DSP), image processing, and specialized hardware accelerators.